In the domain of Web scaling, for example, caching (typically client-based or proxy-based ) is widely seen as the solution to handle the exploding user demands. A large infrastructure for Web caching has been put in place [6, 17, 22]. Although client-based and proxy-based caching greatly help in reducing congestion due to Web traffic in general, a variety of factors undercut their effectiveness: First, not all data is cacheable. Some data may be refreshed at a high rate, which greatly reduces the benefits of caching. Second, caching takes away control. A number of sites are reluctant to have their data cached, for a variety of reasons. The caching mechanisms can be easily bypassed by information providers. For example, the Expire field in the HTTP reply header [5] can be manipulated by the Web server so that the data is never cached by clients. Such sites then become effectively "cache breakers" [18]. The recent severe and widely publicized congestion of NorthWestNet by the release of Microsoft's Internet Explorer 3.0 happened in this way. The practice of circumventing the caching mechanisms puts enough strain on Internet service providers (ISPs) that some have resorted to ignoring the expiration information from a number of sites. Third, mirroring makes caching expensive. Mirrored data is not easily detectable as such by cache systems, and greatly increases the space requirement on caches for them to be effective.
To overcome some of these limitations, a number of push-based methods have been proposed, which give more control to servers about what is being cached [4, 21]. In these schemes, servers push data to the caches, effectively eliminating the problems of cache consistency and the need for mirroring.
With the Internet connectivity becoming truly global, however, new large-scale services, beyond the Web, must be expected. Some of these will be transaction oriented, for which caching is largely ineffective.
In order to support the scaling of the Web and of next-generation IP services, an infrastructure is needed that allows the servers to diffuse load and break up hot spots by dynamically placing appropriately programmed components onto strategically placed nodes in the internetwork, typically "near" large client populations. Such components could be caching agents, mirrors, entire copies of servers, or others, and would run under the server's control. Such a scheme should be able to support current and future IP services, and not rely on a service-specific infrastructure (such as Squid [22] for the Web). In addition, this scheme should remain invisible for the clients.
In this paper, we describe an infrastructure that allows to dynamically replicate IP services to have them adapt to network and server load. This is accomplished by replicating transport-level service access points (in our case TCP and UDP ports) across multiple locations in an internetwork. A distributed server can then be realized by installing multiple ``components'' of the server (for example active caches, or full-sized copies) at different locations in the internetwork. These components then bind to the network, each with its own copy of the same, replicated, transport-level service access point. In this way, the server appears monolithic to the clients, with a single service access point.
In order to test the feasibility of such an approach, we implemented HYDRANET, a protocol infrastructure for service distribution on IP. HYDRANET consists of two components: host servers and redirectors. Host Servers are hosts that act as servers-of-servers. They can host IP services, each of which may be known to the outside world under the IP address of another host. Typically, such services are replicas of the service running on the Origin Host, for example mirrors of sites of a Web server. They can also be scaled-down versions of the service (for example active caches) that run as agents of the server on the origin host. In the following discussion we do not distinguish between full-scale copies of the service on one side and scaled-down versions on the other, but call them all replicas of the service on the origin host, which are each running on one host server.
The location of the host servers is known to the Redirectors, specially equipped routers that maintain information about the host servers and the services installed on them. Redirectors detect requests for replicated services, and redirect the requests to the ``nearest'' available host server with a replica running. A replica-management protocol allows to dynamically install services or remove them, depending on the load in the network and on the servers.
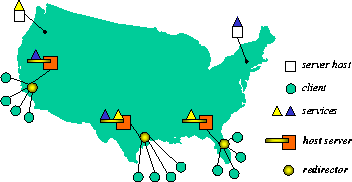
The scenario in Figure 1 gives a general idea of how the components of HYDRANET work together: The two services www.northwest.com and www.northeast.com are accessed by large groups of users from the three ISPs southwest.net, south.net, and southeast.net. Without a replication scheme, the distance from the clients to the servers can cause increased access latencies and network load. In addition, the servers may be overly loaded. In this example, each of the three ISPs routes its traffic through a redirector, and has access to a host server. This allows northeast.com to install a replica for its Web server on the host servers of south.net and southwest.net. Similarly, northwest.com installs replicas on south.net and southeast.net. In this way the network traffic is reduced, and the load balanced, by increasing the service locality. This scenario illustrates how servers, redirectors, and host servers collaborate to bring the services "near" to the clients by conveniently installing replicas on appropriate host servers. In this way, the load on servers and network can be controlled, and hot spots pro-actively diffused.
One immediate concern is that redirectors (which are routers, after all) may be overloaded in this scheme. By strategically placing redirectors and host servers at centers with large client populations at the boundaries of the Internet (for example at large ISPs), significant benefits can be achieved without excessively burdening the routers that now act as redirectors. In addition, our measurements show that redirection adds little overhead in the routers.
In this paper, we present HYDRANET, an infrastructure for dynamic service distribution across an internetwork based on the replication of transport-level service-access points. Section 2 dicusses related approaches for the replication of services and of service access points. Section 3 describes the architecture of HYDRANET, and its realization on a local testbed. We also present the results of a number of performance measurements on HYDRANET. In Section 5 we describe HYDRAWEB, a distributed Web server based on active caches, which we realized on HYDRANET. Section 6 presents the conclusions and an outlook for future work.